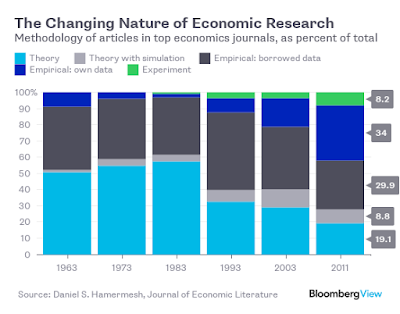
Making causal inferences in economics: Do better grades lead to higher salaries?

In a previous post I discussed the changing nature of the economics profession and the importance of achieving the experimental ideal in social science research. I briefly discussed the logic and even some methodological approaches that are useful in achieving randomization, or at least as-if randomization in order to make our treatment and control groups as similar as possible for comparison. In this post I'll use an example that I like to teach to students to illustrate how we can make causal inferences using natural experiment research designs. A quick reminder: natural experiments are not experiments per se. They only provide us a good way to exploit observational data to emulate an experimental setting. Let's use the very basic example and look at the relationship between student grades and earnings – a topic is usually heatedly discussed among students – do better grades result in higher salaries? Consider the following correlation between grades and earn...